- simple.ai by @dharmesh
- Posts
- OpenAI vs Google vs Anthropic: This Week in AI
OpenAI vs Google vs Anthropic: This Week in AI
Three AI models, three different strengths
Dharmesh Shah
November 26, 2025

The frontier AI race just went into overdrive.
Within the last week, we got three major model releases:
Claude Opus 4.5 from Anthropic
Gemini 3 from Google
GPT-5.1 Pro from OpenAI
This isn't the usual cadence. The big labs are shipping faster, and the models are getting meaningfully better with each release. We've had even more capabilities unlocked that were considered impossible a year ago.
I've spent the last few days testing all three across real work: building agents, coding production features, and running complex research tasks.
So today, I want to break down:
What each model does (and where it excels)
My early testing and honest takes
What this means if you're building with AI

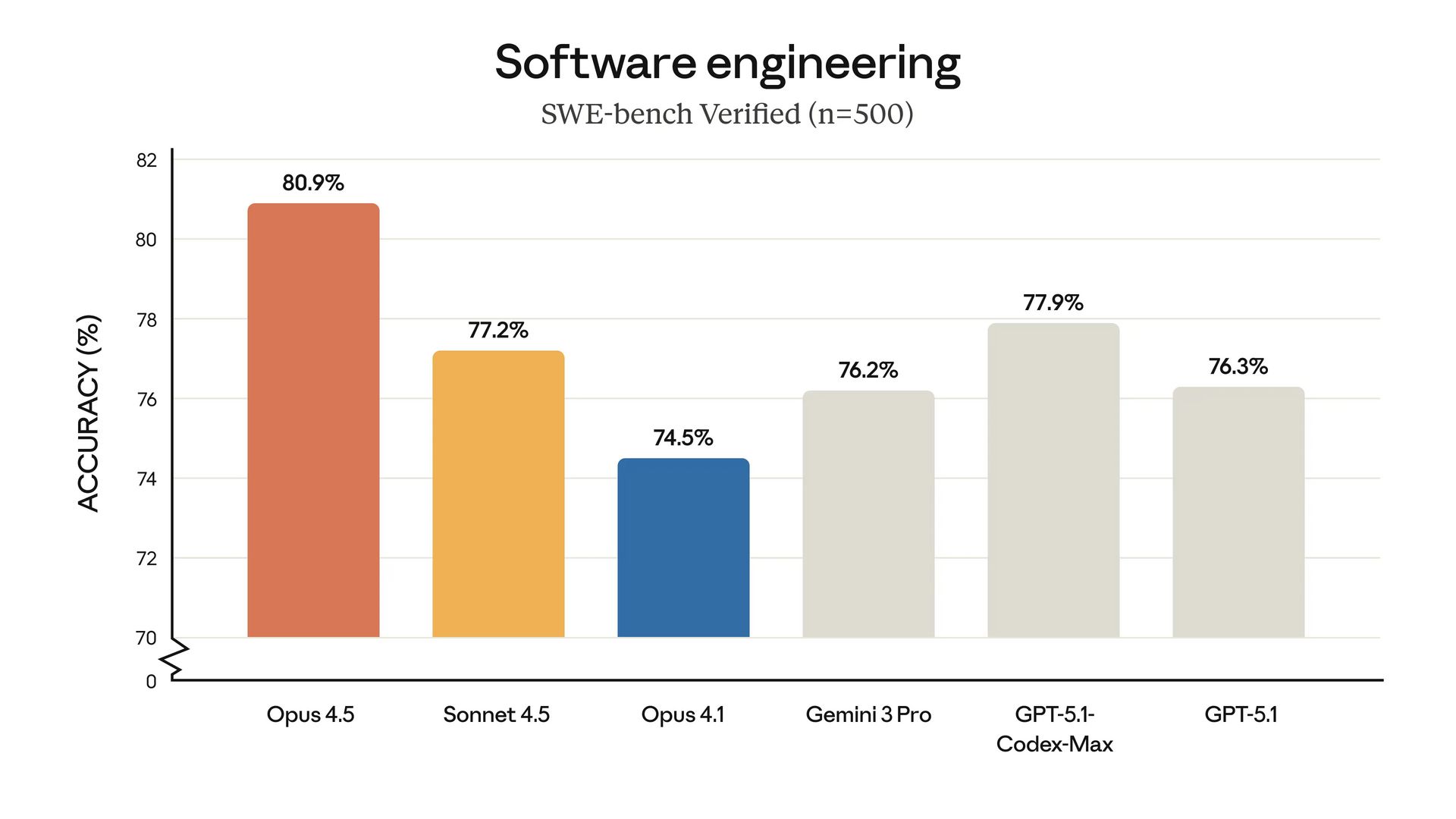
Anthropic’s Claude Opus 4.1 model benchmarks
First up, Anthropic released Claude Opus 4.5, and several of the upgrades are squarely aimed at people like me -- developers building agents.
The headlines:
80.9% on SWE-bench Verified (the benchmark that measures real-world software engineering) -- topping every other model.
It scored better than any human candidate ever on Anthropic's internal performance engineering exam.
On agentic capabilities, Opus 4.5 also leads across the model leaderboard.
But what got me most excited was the tool calling upgrades…
Anyone working with agents runs into this. MCP was a great first step as a protocol, but there's a trade-off: every tool definition loads upfront, consuming tokens before the model starts any real work. Context windows fill up quickly, and performance takes a hit.
Opus 4.5 addresses this with three upgrades:
Tool Search: The model pulls tool definitions on demand rather than loading everything at once. Context windows stay cleaner, responses are faster, and you're not wasting tokens on unused tools. (By the way, it’s very meta — the word, not the company — that Anthropic gave us a tool to search/discover other tools).
Programmatic Tool Calling: Rather than routing every intermediate step back through the model's context, Claude writes code to chain tools together directly. Less like an assistant needing constant updates, more like a developer who understands how to work with APIs. I think a bunch of people were already having this kind of idea (including Anthropic themselves). LLMs are great, but sometimes, introducing layers of abstraction that require using a LLM to make a function call is just not worth it. Let things that can be deterministic (and fast), be deterministic (and fast).
Tool Use Examples: You can demonstrate how to call a tool properly, not just list available parameters. The model follows your examples instead of interpreting your schema in its own creative way.
As agents grow more complex, intelligence isn't the limiting factor -- coordination is. These upgrades make it practical to build agents that handle sophisticated tool workflows without losing track of what they're doing.
Basically, better infrastructure enables better agents.
Oh, and the pricing has dropped as well -- to $5/$25 per million tokens. Previous Opus models were powerful but expensive.
Screenshot of Gemini 3 directly in Google Search’s “AI Mode“
Earlier in the week, Google launched Gemini 3, and I’m seriously impressed. This model is very strong.
The headlines:
Gemini 3 hit 1501 Elo on LMArena, taking the top spot.
On reasoning, it's sitting just behind Opus 4.5.
The model takes the top spot in scientific knowledge, mathematics, and multimodal reasoning.
The one area where it trails (unsurprisingly): coding. Claude Sonnet 4.5 still leads on the SWE-bench Verified benchmark at 77.2%, with Gemini 3 at 76.2%.
That said, the Gemini 3 capability that stands out to me as the big differentiator is how well it works with large context windows (it supports up to 1M tokens like the prior version). So, this could be really useful for agentic coding use cases.
For creative writing though, I'm still reaching for Claude or GPT-5.1 Pro. Gemini 3's outputs feel more functional than lyrical, though this is totally subjective and depends on your task.
I'm also testing it with some Agent.ai agents to see how it performs on multi-step workflows.
In sum, where Gemini 3 clearly wins is context windows, multimodal capabilities, and generative UI. If you need a model that handles video, images, and text together while reasoning across all of it -- and generates interactive experiences in real-time -- Gemini 3 is compelling.
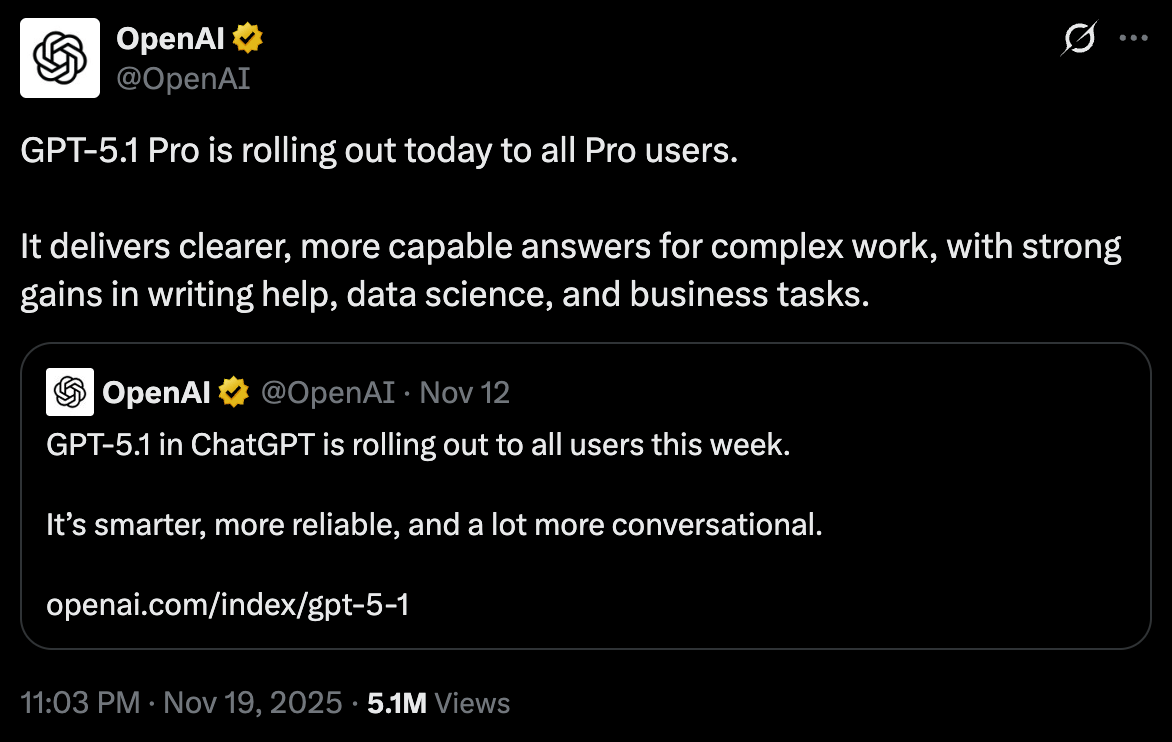
Screenshot from the GPT-5.1 Pro release on Twitter/X
The last major model upgrade that occurred this week was OpenAI's quiet release of GPT-5.1 Pro.
I say quiet because, unlike their typical OpenAI releases, they simply announced the upgrade with a simple tweet (screenshot above). No benchmarks, no blog, just a tweet.
Maybe they’re trying to under-hype and over-deliver, or maybe it’s because the model is only available to Pro subscribers (the top-tier ChatGPT plan), paying $200 a month.
Either way, I’m very impressed with this model. It gives clear answers when handling complex work -- and tops my “vibe test“ over any other model I’ve used in instruction-following, writing, and business strategy work.
The one thing to note is that since the model is part of the Pro plan, responses usually take several minutes, sometimes even longer for complex queries (I’ve had it takeup to 20+ minutes for deep data analysis work).
If you need something quick, this isn't it. If you're working on something critical where mistakes are costly or where you can take rare breakthroughs to the bank -- the wait becomes justified -- and so does this model.
The other big limitation right now is distribution. It's only available through ChatGPT -- No IDE integration, no API access for most use cases. (Lack of an API is why I don’t have a way to give you access to it via agent.ai yet, so you can try it out).
For developers like me, that means context-switching out of your development environment, manually formatting prompts, and copy-pasting results back -- all of which breaks flow when you're deep in flow building something at 2AM in the morning.
What This Means for Builders
At a high level, here’s where the AI models stand after these releases:
Claude Opus 4.5 is focusing on better agent orchestration and tool use -- making complex agentic workflows more reliable.
Gemini 3 is the broad winner, innovating on speed and multimodal understanding -- making AI fast enough for real-time use across text, images, and video.
GPT-5.1 Pro is best for deep reasoning -- making AI capable of handling problems that require genuine expertise.
At a deeper level, we’re seeing divergence in how the models are used (from an API perspective). In the prehistoric times of GPT-3, there was one API call that you passed text in, and the model gave you text back out. Simple. The other models worked the exact same way. So, in essence, you could “swap out” one model for the other relatively easily -- the code was mostly the same.
Now, the way Anthropic does tool discovery and invocation (to supplement MCP) is not available in the other two models, and the way Google Gemini can have video as an input modality is not available in the other two models. This means you can’t just bounce between models on a whim.
If you’re going to take advantage of these kinds of features, you’re going to have to code to the specific model and its implementation. We’ll certainly have efforts to create abstraction layers that sit above the models to make it easy to move between them, but increasingly, those abstraction layers are going to get leaky. We’re no longer living in a world of simple text completion APIs.
Speaking of which, one thing I didn’t get a chance to talk about in this post was Google’s release of Nano Banana Pro, their fantastically good image generation model. I’m already using it to great effect in ImageGen.ai (the AI agent for generating images for business use). You should really try it out.
Here’s an example of what I created with a single prompt using this post as the content:
But all in all, it’s been a great week, and I’ll close out this post with my usual line:
It’s time to build! 🙂
—Dharmesh (@dharmesh)


What'd you think of today's email?Click below to let me know. |