- simple.ai by @dharmesh
- Posts
- Stop Opening *7 Tabs* to Test AI Models
Stop Opening *7 Tabs* to Test AI Models
With this agent you can compare all of them...all at once
Dharmesh Shah
December 11, 2025

I do this more often than I'd like to admit: I have a prompt I want to run for a complex task, so I open Claude, then ChatGPT in another tab, then Gemini, then Perplexity.
I paste the same prompt into each one, wait for all the responses, and try to figure out which answer is better.
It's tedious, and it’s easy to lose track of which model said what.
But the thing is, each AI model is good at different things. Claude's great for coding, GPT-5 is strong on reasoning, Gemini handles long context well, and Perplexity searches the best.
Despite the benchmarks on the internet, you just don't know which one will give you the best answer for your specific prompt until you try them all.
That's where this new agent I found on Agent.ai comes in handy.
It runs one prompt across multiple AI models at once and shows you all the responses side-by-side, so you don't have to keep switching tabs -- or waste time copying/pasting their answers to one place.
So today, I want to break down:
Why comparing models matters
What I'm using the new agent for
How teams can make the most of it

Why comparing models matters more than you'd think
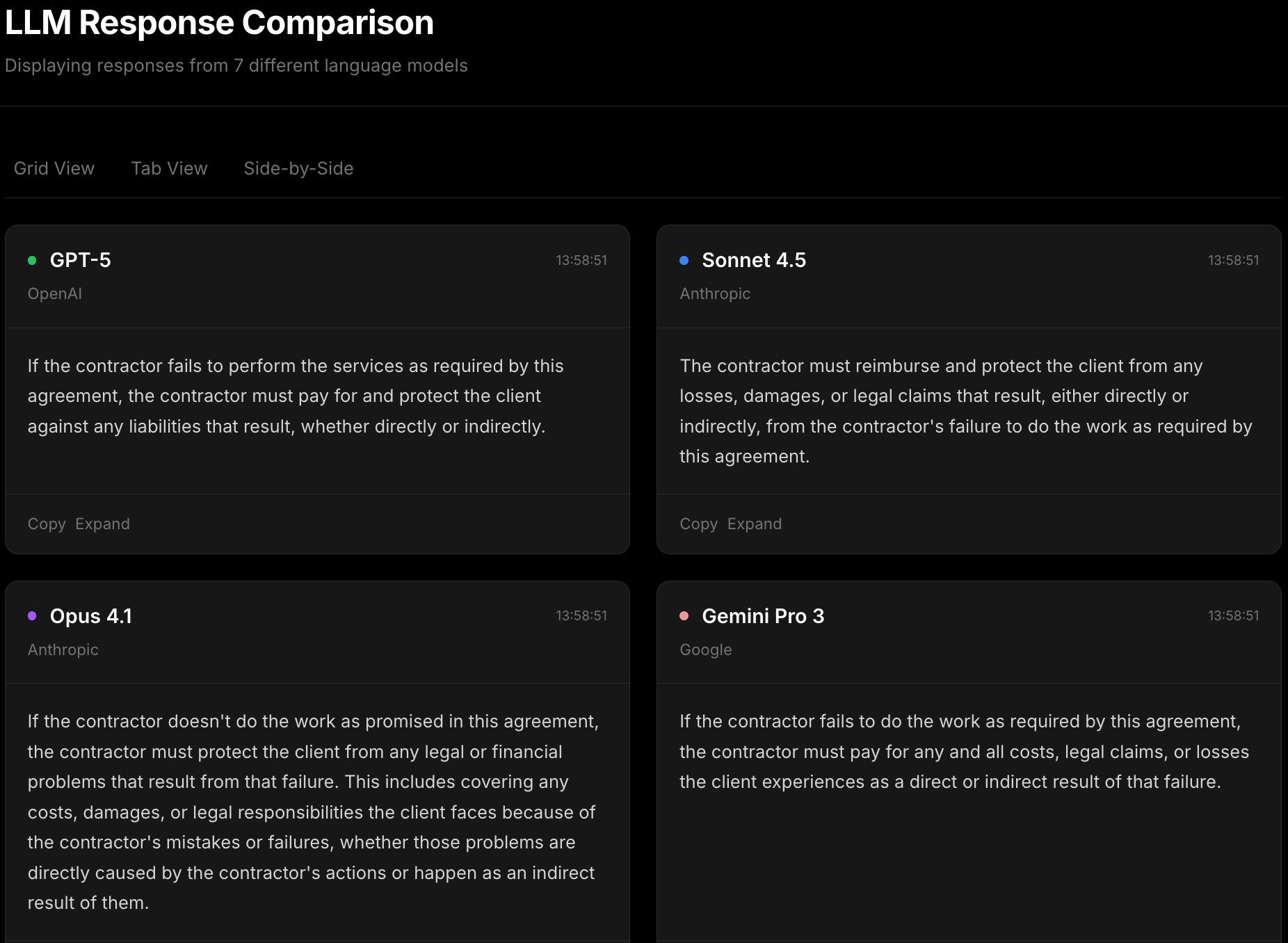
I tested a prompt with a legal clause that needed to be rewritten in plain English:
"The contractor shall indemnify the client against any and all liabilities arising directly or indirectly from the contractor's failure to perform the services in accordance with this agreement."
Each model took a different approach:
GPT-5 kept it short and direct
Claude Sonnet 4.5 was more thorough with the explanation
Opus 4.1 added extra context about what the contractor's failure actually means
Gemini Pro 3 also went for simple and straightforward
None were wrong, but they weren't the same either. Depending on who's reading it -- a client, a legal team, an operations person, or a business head -- you might want different versions.
This is pretty useful when you're using AI for real work. The comparator lets you see these differences immediately instead of running the same prompt multiple times and trying to remember which response came from where.
And in cases where an AI can make an error -- like getting numbers wrong in a report or mixing up facts -- having multiple responses in one view makes it easier to spot those issues before they become real problems.
(By the way, I do this for my coding uses cases mostly, but used this legal example for simplicity purposes because I know not everyone can read code).
What I'm using it for

AI Response Comparator
I've found AI Response Comparator helpful for specific scenarios:
Testing tone -- For customer-facing content, I can see which model gets closer to the tone I'm going for.
Looking for issues -- For anything sensitive, like code, I want to see if any models make stuff up. The side-by-side comparison makes this easier to spot.
Learning patterns -- Over time, I'm learning which models work better for which tasks through actual testing. This is making my work easier.
The workflow is also pretty straightforward.
Just enter your prompt, hit go, and wait a couple of minutes while it queries all new, mainstream models -- from GPT-5 to DeepSeek. Once done, you get responses in three view options: grid (see everything at once), tab (focus on one model at a time), and side-by-side (compare two directly).
You can also add this agent to Slack. This way, instead of launching agent.ai separately, you can trigger the service and the comparator right where you're working with business information and relevant context.
How teams can make the most of it
I've been talking to some companies where teams are adopting AI, and they keep coming back to the same question: which model should we actually use?
Product teams want to know which model writes clearer customer emails, operations teams need to know which one is better at summarizing documents, marketing teams want the model that matches their brand voice.
The list goes on and on.
This agent is pretty useful at turning this process into something more transparent and measurable. You run your prompts through one interface to compare multiple models and make a more informed decision about which AI model works best for which task.
By the way, agent.ai is currently free to use (takes just a minute to sign up).
Some things that I think might be worth testing:
A factual question where accuracy matters
A writing task where tonality matters
A technical query to see which models hallucinate
I'd love to hear what you find. Tag me if you discover something interesting about how different models handle the same prompt.
—Dharmesh (@dharmesh)


What'd you think of today's email?Click below to let me know. |